友链:
- https://github.com/tensorflow/tensorflow
- https://github.com/tensorflow/tensorboard
- https://github.com/tensorflow/models
- https://tensorflow.google.cn/
tensorflow中文文档:https://tf.wiki/- https://github.com/dragen1860/TensorFlow-2.x-Tutorials
keras中文文档:https://github.com/keras-team/keras-docs-zh- https://github.com/keras-team/keras
- keras模型入门教程:40题刷爆Keras,人生苦短我选Keras
- 官方文档太辣鸡?TensorFlow 2.0开源工具书,30天「无痛」上手
想要系统学习tensorflow的小伙伴,推荐友链中的tensorflow中文文档和keras中文文档,这篇博客中的内容都摘自这俩中文文档,仅用来记录我自己的学习历程。

在 TensorFlow 2 中,即时执行模式将成为默认模式,无需额外调用 tf.enable_eager_execution() 函数(不过若要关闭即时执行模式,则需调用 tf.compat.v1.disable_eager_execution() 函数)。
TensorFlow 安装与环境配置
conda虚拟环境:
1 | conda create --name [env-name] # 建立名为[env-name]的Conda虚拟环境 |
TensorFlow基础
python的with语句:
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
参考:
https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonwith/index.html
张量
TensorFlow 使用 张量 (Tensor)作为数据的基本单位。TensorFlow 的张量在概念上等同于多维数组,我们可以使用它来描述数学中的标量(0 维数组)、向量(1 维数组)、矩阵(2 维数组)等各种量。
张量的重要属性是其形状、类型和值,可以通过张量的 shape 、 dtype 属性和 numpy() 方法获得。
TensorFlow 的大多数 API 函数会根据输入的值自动推断张量中元素的类型(一般默认为 tf.float32 )。不过你也可以通过加入 dtype 参数来自行指定类型,例如 zero_vector = tf.zeros(shape=(2), dtype=tf.int32) 将使得张量中的元素类型均为整数。张量的 numpy() 方法是将张量的值转换为一个 NumPy 数组。
1 | # 查看矩阵A的形状、类型和值 |
TensorFlow 的大多数 API 函数会根据输入的值自动推断张量中元素的类型(一般默认为 tf.float32 )。不过你也可以通过加入 dtype 参数来自行指定类型,例如 zero_vector = tf.zeros(shape=(2), dtype=tf.int32) 将使得张量中的元素类型均为整数。张量的 numpy() 方法是将张量的值转换为一个 NumPy 数组。
自动求导机制
TensorFlow 提供了强大的 自动求导机制 来计算导数。在即时执行模式下,TensorFlow 引入了 tf.GradientTape() 这个 “求导记录器” 来实现自动求导。
1 | # 计算函数 y(x) = x^2 在 x = 3 时的导数: |
与普通张量一样,变量同样具有形状、类型和值三种属性。使用变量需要有一个初始化过程,可以通过在 tf.Variable() 中指定 initial_value 参数来指定初始值。变量与普通张量的一个重要区别是其默认能够被 TensorFlow 的自动求导机制所求导,因此往往被用于定义机器学习模型的参数。
tf.GradientTape() 是一个自动求导的记录器。只要进入了 with tf.GradientTape() as tape 的上下文环境,则在该环境中计算步骤都会被自动记录。比如在上面的示例中,计算步骤 y = tf.square(x) 即被自动记录。离开上下文环境后,记录将停止,但记录器 tape 依然可用,因此可以通过 y_grad = tape.gradient(y, x) 求张量 y 对变量 x 的导数。
TensorFlow 下的线性回归

1 | import numpy as np |

TensorFlow 模型建立与训练
- 模型的构建: tf.keras.Model 和 tf.keras.layers
- 模型的损失函数: tf.keras.losses
- 模型的优化器: tf.keras.optimizer
- 模型的评估: tf.keras.metrics
Keras:model和layer
Keras 是一个广为流行的高级神经网络 API,简单、快速而不失灵活性,现已得到 TensorFlow 的官方内置和全面支持。
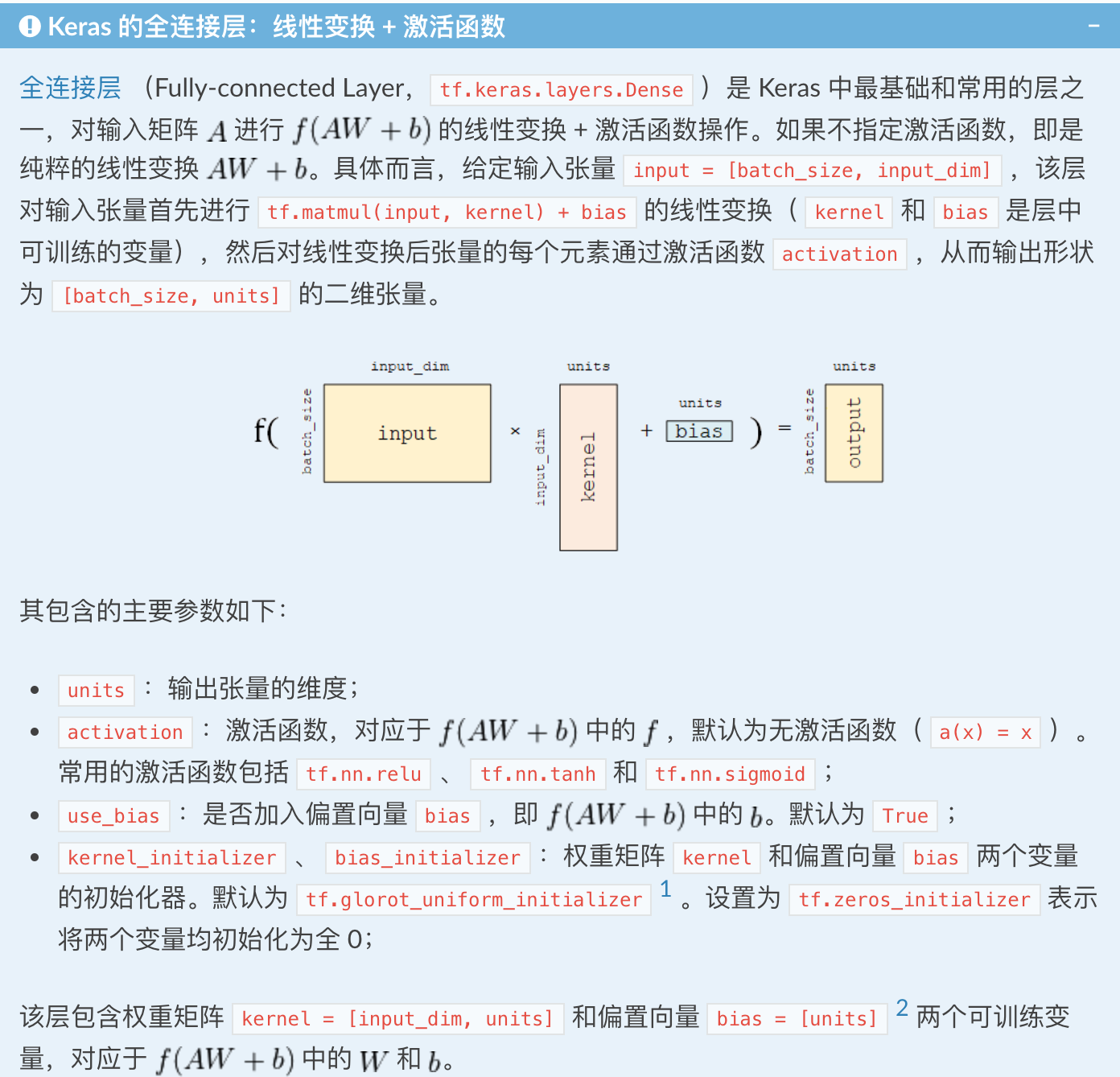
Keras 有两个重要的概念: 模型(Model)和 层(Layer)。层将各种计算流程和变量进行了封装(例如基本的全连接层,CNN 的卷积层、池化层等),而模型则将各种层进行组织和连接,并封装成一个整体,描述了如何将输入数据通过各种层以及运算而得到输出。
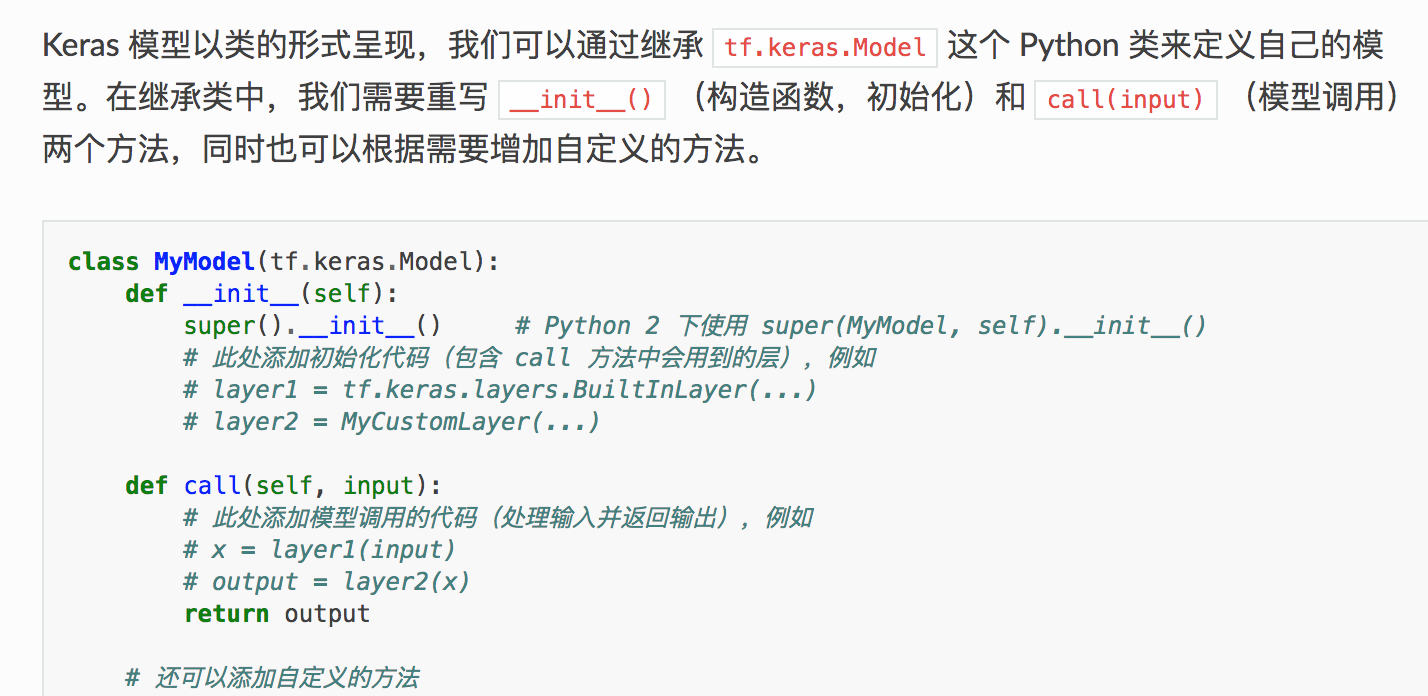
Keras 模型类定义示意图 :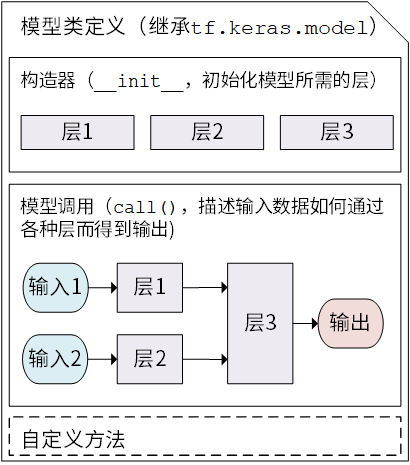
通过模型类的方式编写线性模型:
1 | import tensorflow as tf |
多层感知机(MLP,多层全连接神经网络)
- 数据获取及预处理 MNISTLoader()
- 模型的构建 MLP(tf.keras.Model)
- 模型的训练:tf.keras.losses 和 tf.keras.optimizer
- 定义一些模型超参数
- 实例化模型和数据读取类,并实例化一个 tf.keras.optimizer 的优化器
- 从 DataLoader 中随机取一批训练数据;
- 将这批数据送入模型,计算出模型的预测值;
- 将模型预测值与真实值进行比较,计算损失函数(loss)。这里使用 tf.keras.losses 中的交叉熵函数作为损失函数;
- 计算损失函数关于模型变量的导数;
- 将求出的导数值传入优化器,使用优化器的 apply_gradients 方法更新模型参数以最小化损失函数
- 模型的评估: tf.keras.metrics
1 | class MNISTLoader(): |
交叉熵
在 tf.keras 中,有两个交叉熵相关的损失函数 tf.keras.losses.categorical_crossentropy 和 tf.keras.losses.sparse_categorical_crossentropy 。其中 sparse 的含义是,真实的标签值 y_true 可以直接传入 int 类型的标签类别。具体而言:
1 | loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred) |
与
1 | loss = tf.keras.losses.categorical_crossentropy( |
的结果相同。
https://blog.csdn.net/tsyccnh/article/details/79163834
卷积神经网络(CNN)
1 | class CNN(tf.keras.Model): |
1 | import tensorflow as tf |
循环神经网络(RNN)
。。。
深度强化学习(DRL)
。。。
TensorFlow 常用模块
tf.train.Checkpoint 变量的保存与恢复

1 | # train.py 模型训练阶段 |
tensorboard 训练过程可视化
整体框架如下:
1 | summary_writer = tf.summary.create_file_writer('./tensorboard') |
当我们要对训练过程可视化时,在代码目录打开终端(如需要的话进入 TensorFlow 的 conda 环境),运行:
1 | tensorboard --logdir=./tensorboard |
然后使用浏览器访问命令行程序所输出的网址(一般是 http:// 计算机名称:6006),即可访问 TensorBoard 的可视界面。
tf.data 数据集的构建与预处理
TFRecord TensorFlow 数据集存储格式
tf.function 图执行模式
TensorFlow 2 为我们提供了 tf.function 模块,结合 AutoGraph 机制,使得我们仅需加入一个简单的 @tf.function 修饰符,从而将模型转换为易于部署且高性能的 TensorFlow 图模型。
只需要将我们希望以图执行模式运行的代码封装在一个函数内,并在函数前加上 @tf.function 即可。

1 | import tensorflow as tf |
一般而言,当模型由较多小的操作组成的时候, @tf.function 带来的提升效果较大。而当模型的操作数量较少,但单一操作均很耗时的时候,则 @tf.function 带来的性能提升不会太大。
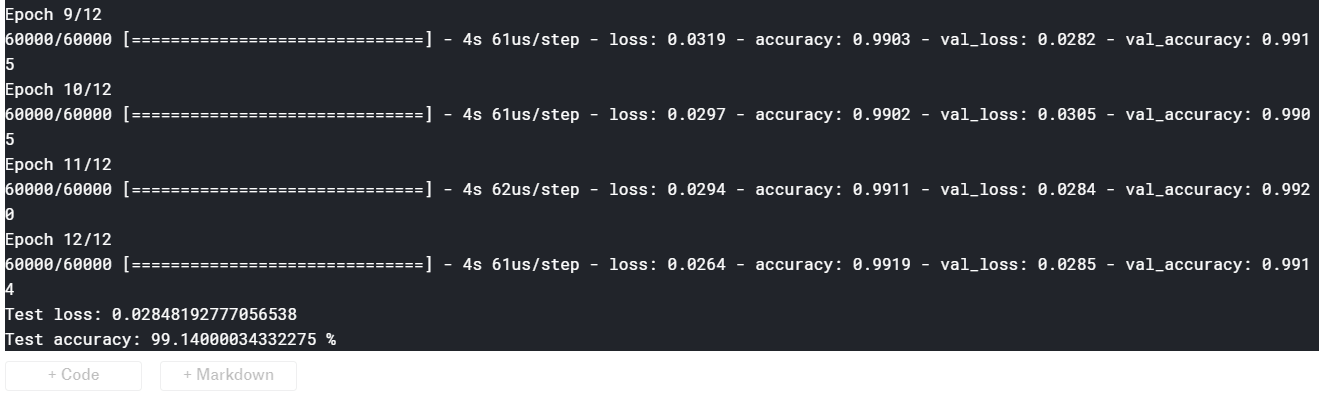
附一个kaggle上mnist手写体识别的code:
1 | from __future__ import print_function |